如果您还没有听说过Dvorak(德沃夏克)键盘布局,可以先从维基百科上了解一下相关背景:
http://zh.wikipedia.org/wiki/德沃夏克鍵盤
我是一个重度的Dvorak使用者,倘若给我一副普通的Qwerty键盘,我只能盯着它,用两个手指“戳字”。我的相册中有一张图片,是我正在使用的Macbook,按键已经被我重新排了座次。
Google了一通,似乎目前最快最流行的速记方法称为“亚伟速录”,使用专门定制的键盘和输入法。尽管无法在电脑上模拟,但是其核心内容大概有三点可以吸取:
- 根据中文习惯重新安排了键位,常用按键在中间一排。
- 将多个字符组成的韵母安排在了固定的按键上,类似“双拼”,只用输入一个字符。
- 如同使用乐器一般,多个按键可以同时按下。
Dvorak键盘布局下中文输入法的讨论几乎是个空白,我想在这一系列文章中对上面三点逐一分析,看看是否能够找到一些提高录入速度的办法。今天是第一部分,对Dvorak在中文输入的键位安排方面做一点研究。
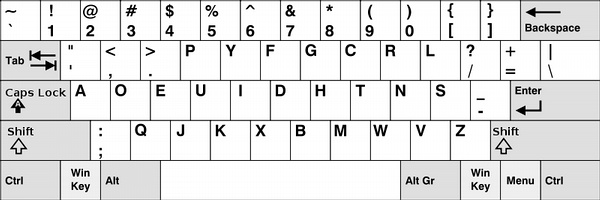
在Dvorak键盘布局下,英文最常用的字母被安排到了手指最容易按到的地方。对这一点的研究已经很多,不用质疑。可是用来输入中文(拼音)的情况又是怎么样呢?
从前有人对汉字字符集做过统计,在Dvorak布局下,键盘的中排使用率要明显高于Qwerty,这也就意味着同输入英文一样,输入汉语拼音也能从该布局中受益,手指移动的距离更少。但是对字符集的统计毕竟代替不了实际情况,因为在实际输入中,各个汉字的使用频率不同,可能造成实际的使用结果与对字符集的统计存在差别。所以Dvorak的效率究竟如何,还要在实践中检验。
在下面这段Python代码中,我对自己以前撰写的几篇稿件进行了分析。这些稿件内容大多与IT相关,字数约为五、六万。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
__author__ = "ldx (lispython@gmail.com)"
__date__ = "Sat Sep 26 08:02:00 2009"
#from pinyin import hanzi2pinyin
from hanzimap import hanzi2pinyin
import collections
import numpy as np
import matplotlib.pyplot as plt
doc = open('doc.txt', 'r').read()
rst = hanzi2pinyin(doc.decode('utf8'))
result = {}
# print rst.count('iong')
data = collections.defaultdict(int)
all_keys = '\',.;abcdefghijklmnopqrstuvwxyz'
dv_rows = ['\',.pyfgcrl', 'aoeuidhtns', 'qjkxbmwvz']
qw_rows = ['qwertyuiop', 'asdfghjkl', 'zxcvbnm,.']
for char in rst:
if char in all_keys:
data[char] += 1
data['letters'] += 1
for c in all_keys:
result[c]=(float(data[c])/data['letters']*100)
dv = [0,0,0]
qw = [0,0,0]
for i in range(3):
for c in dv_rows[i]:
dv[i] += result[c]
for i in range(3):
for c in qw_rows[i]:
qw[i] += result[c]
keys = result.keys()
keys.sort()
val = [result[key] for key in keys]
plt.figure(1, figsize=(8,8))
ax = plt.axes([0.1, 0.1, 0.8, 0.8])
labels = ('up', 'middel', 'down')
explode = (0.05, 0.05, 0.05)
plt.pie(dv, explode=explode, labels=labels, autopct='%1.1f%%', shadow=True)
plt.title('Dvorak', bbox={'facecolor':'0.8', 'pad':5})
plt.figure(2, figsize=(8,8))
plt.pie(qw, explode=explode, labels=labels, autopct='%1.1f%%', shadow=True)
plt.title('Qwerty', bbox={'facecolor':'0.8', 'pad':5})
pos = np.arange(0, 60, 2)
plt.figure(3)
plt.barh(pos, val, 1.5, align='center', alpha = 0.8)
plt.yticks(pos, keys)
plt.xlabel('Percentage')
plt.grid(True)
plt.show()
对于这段代码有几点需要说明:
- 将汉字转换为拼音使用了pyzh中的pinyin模块,但是该模块不能将中文标点转换为英文标点进行统计,因此我做了一点修改,将其命名为hanzimap。
- 代码中使用了matplotlib库(同样也不在标准库中),将统计结果生成图像。
- 中文文稿样本为doc.txt,使用utf-8编码,与代码放在同一目录下。文稿中的空白不会影响最后结果。
结果如下:
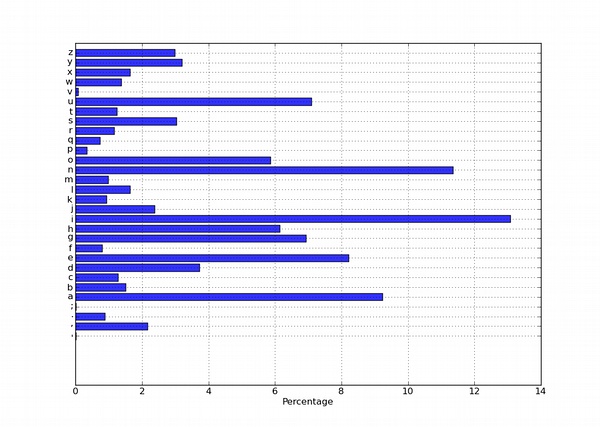
分别在Qwerty和Dvorak布局下,键盘的上、中、下三排使用情况对比。
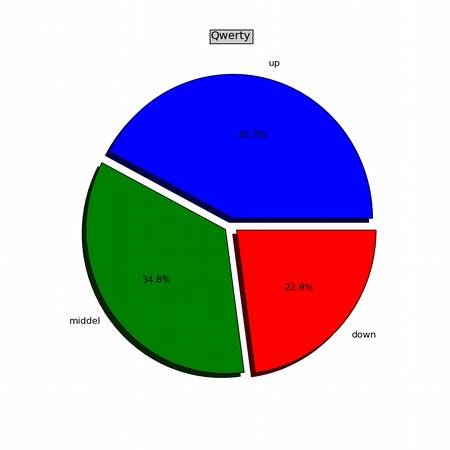
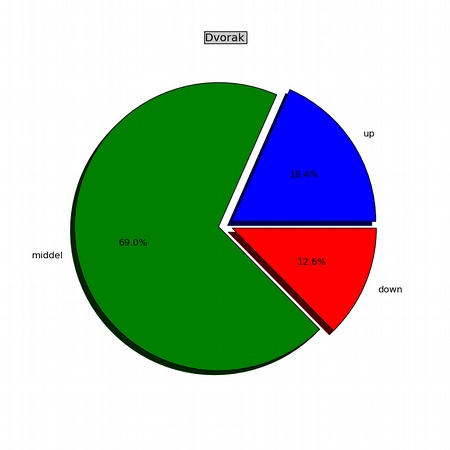
我们可以看到(清晰一些的图片可以在我的相册中浏览)Qwerty布局中间一排的使用率为34.8%,甚至还不如上面一排。
Dvorak布局下,中排的使用率则达到了69%,几乎是Qwerty布局的两倍。稍微有点儿可惜的是处于上面一排的字母g,它的使用率很高,甚至高过了中排的许多字母,不过好在该字符位于右手食指上方,是除中排以外最容易触到的按键。